
Applets
contents
visual index
 introduction std_logic_1164 gatelevel circuits delay models flipflops adders and arithm... counters LFSR and selftest memories programmable logic state-machine editor misc. demos I/O and displays DCF-77 clock relays (switch-le... CMOS circuits (sw... RTLIB logic RTLIB registers Prima processor D*CORE MicroJava Pic16 cosimulation
introduction std_logic_1164 gatelevel circuits delay models flipflops adders and arithm... counters LFSR and selftest memories programmable logic state-machine editor misc. demos I/O and displays DCF-77 clock relays (switch-le... CMOS circuits (sw... RTLIB logic RTLIB registers Prima processor D*CORE MicroJava Pic16 cosimulation Mips R3000 cosimu...
Mips R3000 cosimu... TinyMips int... TinyMips Sieve TinyMips stack TinyMips mul... TinyMips loa... TinyMips mul... TinyMips wit... TinyMips UAR... TinyMips UAR... TinyMips int... TinyMips int... Mips fast Sieve TinyMips wit... Mips - game ... Mips prime n... Intel MCS4 (i4004) image processing ... [Sch04] Codeumsetzer [Sch04] Addierer [Sch04] Flipflops [Sch04] Schaltwerke [Sch04] RALU, Min... [Fer05] State-Mac... [Fer05] PIC16F84/... [Fer05] Miscellan... [Fer05] Femtojava FreeTTS
TinyMips int... TinyMips Sieve TinyMips stack TinyMips mul... TinyMips loa... TinyMips mul... TinyMips wit... TinyMips UAR... TinyMips UAR... TinyMips int... TinyMips int... Mips fast Sieve TinyMips wit... Mips - game ... Mips prime n... Intel MCS4 (i4004) image processing ... [Sch04] Codeumsetzer [Sch04] Addierer [Sch04] Flipflops [Sch04] Schaltwerke [Sch04] RALU, Min... [Fer05] State-Mac... [Fer05] PIC16F84/... [Fer05] Miscellan... [Fer05] Femtojava FreeTTSBasically, the mission of hardware-software cosimulation is to find bugs in either the hardware or software or the interaction of both. Given the complexity of current embedded systems and their software, the performance of the simulation is often critical, and a careful trade-off between the modeling of details and the resulting simulator performance must be found. For example, it is wasteful to spend all the simulator activity on the details of the system bus transactions, once initial simulations have confirmed that the system bus works as designed. From then on, a higher abstraction level with less details but higher performance could be used for the following simulations.
The TinyMipsWithOnchipRam component demonstrated here integrates the TinyMips processor core with an internal memory component, whose start address and size of this memory block are user-configurable. The default memory size is 64 KBytes starting at physical address zero, corresponding to the MIPS address range is 0000.0000 - 0000.3ffc. The internal memory is implemented as a standard array of 32-bit integer words and all accesses to this internal memory block are replaced by fast array accesses. No external bus events are generated by the processor during such cycles. On the other hand, for all memory accesses to addresses outside the internal (on-chip) memory, the processor faithfully drives the address-bus and the nWR and nRD write- and read-control signals with the appropriate timing. This strategy combines the best of both worlds: accesses to the internal memory are very fast, but accesses to peripheral devices or external memories use the correct bus-timing and can still be simulated in full detail.
As a first demonstration of the better simulator performance, this applet again uses the Sieve of Eratosthenes algorithm. The on-chip memory of the TinyMipsWithOnchipRam is used to hold the binary-program and the heap and stack data generated during the program execution. Therefore, the hardware for this applet consists of just the processor and the reset and clock generators. Click here to go back to the original applet with TinyMips processor and its external MipsRAM memory.
The Sieve of Eratosthenes algorithm
The algorithm demonstrated in this applet uses a series of simple integer-only operations to calculate a list of prime numbers. No multiplications or divisions are required for this.The C source code of the Sieve algorithm is shown below. The 'limit' variable defines the size of the sieve matrix, whose starting position is given by the hardcoded value of the 'sieve' pointer variable. In the example below the values 'limit=8192' and 'sieve=0x00000400' were chosen, so that the sieve matrix starts near the end of the program code, and it is possible to watch instruction fetch accesses and sieve write accesses in the memory editor at the same time.
The program consists of four subsequent stages. The first stage initializes the sieve matrix in the address range sieve..sieve+limit with a constant value 0xcccccccc. This value is more or less arbitrary, and was chosen because it is visually quite different from small integer values like 0x00000007 and therefore easy to spot in the memory editor.
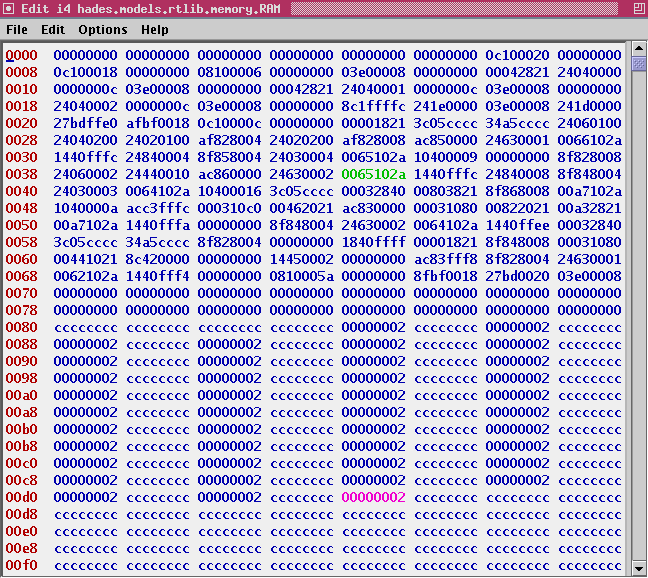
Click here for a screenshot of the memory editor after the first few iterations of the loop. The next loop marks all multiples of two in the sieve array. The idea of the loop is to mark all numbers that are divisible by two as non-prime.
{kind=link}
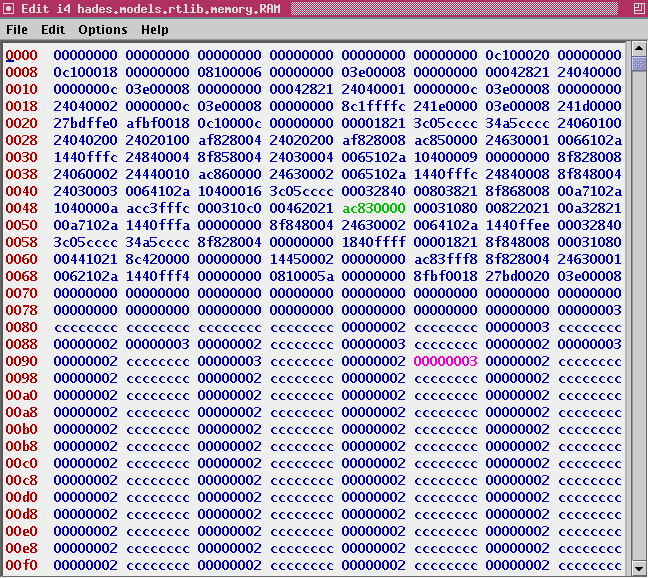
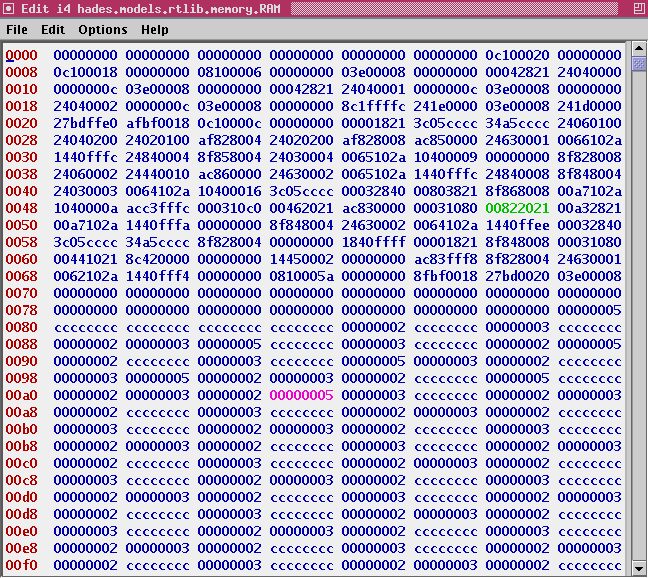
The third stage of the program consists of two nested loops and forms the heart of the sieve algorithm. The outer loop steps through all uneven numbers (3,5,7,..) up to the limit value. Naturally, we could also iterate through all numbers (2,3,4,5,6,...) but the previous loop has already marked all even numbers as non-prime. The inner loop marks all multiples of the currently active outer variable. Click here and here for screenshots of the memory editor after the first few iterations of the inner loop with values 3 and 5 as the outer loop variable. Once the outer loop finishes, all non-prime numbers inside the sieve array have been marked with their largest divisor, while the prime numbers still retain their initialization value 0xcccccccc.
{kind=link}
{kind=link}
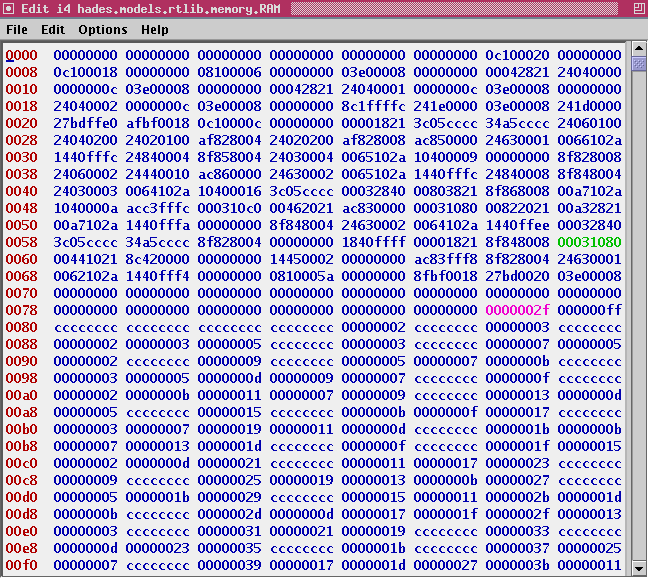
The final endless loop of the program steps through the sieve array. If the value in question still retains the marker value 0xcccccccc, the number is prime and its value is written to address sieve-2. The following screenshot shows the memory editor during execution of the final loop, with the value 0x2f (decimal 47) written to location sieve-2 as one of the calculated prime numbers. Make sure to check the values inside the sieve array starting at memory address 0x0400.
Usage
Wait until the applet is loaded, then use the popup-menu (via popup > edit) to open the user-interface of the processor which (at the moment) consists of two separate memory-editor windows. The first editor shows the processor registers, while the second editor shows the on-chip memory contents. The program uses the following memory-map:
Mips addresses usage 0000.0000 - 0000.000f unused 0000.0010 program start address 0000.0010 - 0000.0298 binary program (sieve algorithm) ... - 0000.02fc stack (grows downwards) 0000.03f8 status variable (prime numbers) 0000.03fc status variable (tmp loop count) 0000.0400 - 0000.83fc sieve array
Again, the memory editor highlights the last read operation in green color, and the last write operation in cyan color, which allows you to easily watch the program execution. By default, the memory editor shows the more compact hexadecimal view of the memory contents, but you switch to the detailed disassembled view via its menu bar. To select either mode, open the format submenu from the editor's menu bar via menu>edit>format>hex, then select the corresponding view.
If you want to change the simulation speed, just select 'edit' on the clock-generator component, then edit the value of the clock-generator 'period' property, and select 'apply' (and 'ok' to close the clock-generator config dialog).
Similarly, open the TinyMips user-interface window (via popup > edit) to watch the register contents during the program execution.
The binary program running on the processor was compiled and linked with the GNU gcc (2.7.2.3) and binutils cross-compiler toolchain on a Linux x86 host, with the final ELF loading and relocation done via the Hades Elf2rom tool. See
- C source code
- disassembled ELF file
- memory-initialization file
- build-script/batch-file
- TinyMips sources (JAR archive)
/* sieve of Eratosthenes to demonstrate TinyMips in Hades */
int main( int argc, char** argv ) {
int i;
int j;
int limit = 8192; // size of sieve
int *sieve = (void*) 0x00000400; // start address of sieve
// initialization loop
for( i=0; i < limit; i++ ) {
*(sieve+i) = 0xCCCCCCCC;
}
// first loop iteration marks all multiples of 2
for( i=4; i < limit; i = i+2 ) {
*(sieve+i) = 2;
}
// next nested loop marks all multiples of 3,5,7,...
for( i=3; i < limit; i = i+2 ) {
*(sieve-1) = i;
for( j=(i+i); j < limit; j = j+i ) {
*(sieve+j) = i;
}
}
// endless loop that writes the detected primes to *(sieve-2)
for( ;; ) {
for( i=0; i < limit; i++ ) {
if (*(sieve+i) == 0xCCCCCCCC) {
*(sieve-2) = i;
}
}
}
}