1971: Intel bringt den 4004 auf den Markt. 108 kHz, 2300 Transistoren
1974: Der Nachfolger 8080 kommt heraus, wird hauptsächlich zur Maschinensteuerung eingesetzt.
2 MHz 6000 Transistoren.
Motorola präsentiert den ersten 8-Bit-Prozessor, den 6808.
1975: AMD bringt den 8080A heraus.
Die von zwei ehemaligen Intel-Mitarbeitern gegründete Firma Zilog präsentiert den 8-Bit-Prozessor Z80: Ist Schneller und verarbeitet mehr Befehle als der 8080.
1977: Apple stellt den Apple II „PC“ mit einem 6502-Prozessor vor.
1978: Intels 8086 kommt auf den Markt. Er ist der Ur-Prozessor: Alle folgenden Intel-Produkte werden zu diesem kompatibel sein. 5 MHz, 29000 Transistoren, 16 Bit. Später wird dieser Prozessor auf 10 MHz aufgestockt. Er kann dann bis zu 330.000 Befehle pro Sekunde abarbeiten.
Es werden verschiedene Lizenzen zum Nachbau des 8086 vergeben. Diese Lizenzbauten anderer Firmen sind zum Teil schneller als das Original, so zum Beispiel der V20 von NEC.
1979: Intel präsentiert den Billigprozessor 8088, intern 16Bit, extern aber nur 8 Bit.
Motorola stellt den 68000 vor (68000 Transistoren, sehr schnell).
1980: Siemens kann seine ersten x86-Prozessoren verkaufen: die SAB 8086 und 8088.
1981: IBM beginnt mit dem Verkauf von PCs. Zwar ist der 68000 von Motorola wesentlich leistungs- fähiger, doch entschließt man sich für den Einbau des Intel 8088: Motorola kommt mit der Produktion nicht hinterher. Da man die Rechnerarchitektur nicht patentieren lässt, bauen viele Firmen IBM-kompatible Rechner, die Marktbeherrschend werden.
AMD präsentiert seinen eigenen 8086.
1982: Intel stellt den 80286 (130.000 Transistoren, 16 Bit) vor. Die Zusatzbezeichnung AT steht für „Advanced technology“. Siemens zieht mit dem SAB 80286 gleich, während sich der Rückstand von AMD (Präsentation des 8088) langsam zeigt.
1984: Motorola präsentiert mit den 68010 und 68020 die ersten 32-Bit-Prozessoren.
Die Auslieferung des Apple Macintosh beginnt.
AMD entwickelt den Am286 mit 16 MHz.
1985: NEC und Intel ziehen mit dem V60 bzw. 80386 (275.000 Transistoren, 16 MHz, später 20, 25 und 33 MHz) mit Prozessoren mit 32 Bit nach.
1986: Compaq baut als erster PC-Hersteller den 80386 ein.
Commodore liefert den Amiga mit dem 68000er.
Intel gewinnt einen schon 1984 begonnenen Urheberrechtsprozess gegen NEC und vergibt fortan keine Lizenzen mehr außer an IBM. Die eigenen FERTIGUNGSANLAGEN WERDEN AUSGEBAUT.
1987: Neue Rechner sind nicht mehr abwärtskompatibel, da anstatt des bisher benutzten ISA-Busses ein sogen. Mikrokanal verwendet wird, aber EISA und ISA setzen sich in den nächsten Jahren durch.
April 1988: AMD präsentiert eine Weiterentwicklung des 286, der 386-Niveau erreicht.
Juni 1988: Da sich Intels 386 nur sehr schleppend verkauft, produziert man eine Billigausgabe mit nur 16 statt 32 Bit (80386SX). Mit einer großen Werbekampagne wird versucht, den 286 für tot zu erklären, da auf dem 286-Markt immer noch große Konkurrenz herrscht, während man mit dem 386 Segmentbeherrschend war (AMD war aufgrund des technologischen Rückstands von jetzt 3 Jahren bedeutungslos). Das Logo „Intel inside“ wird eingeführt.
April 1989: Intels neues Flaggschiff, der 80486 (1,2 Mio. Transistoren, 25MHz, bis 1994 auf 100 MHz erhöht) ist der Erste mit integriertem Coprozessor. Aufgrund meist langsamerer Komponenten arbeitet er mit 8 KB Cache und einer intern höheren Taktrate als extern.
1991: AMD präsentiert einen Clone von Intels 80386DX.
Intel und IBM unterzeichnen 10-Jahres-Vertrag zur gemeinsamen Entwicklung von Prozessoren.
1992: Cyrix kommt mit dem 386SX-Clone Cx486SLC mit 25MHz.
Intel bekommt in einem Prozess um unerlaubte Verwendung des Microcodes bei AMD einen Teilerfolg: AMD darf den Code nicht mehr verwenden. AMD stellt die Produktion von Coprozessoren ein und stürzt sich auf die Entwicklung eines 486-Nachbaus, falls das Gericht auch für weitere Prozessor-Generationen eine Verwendung verbieten würde. Doch AMD gewinnt noch in diesem Jahr den Prozess.
März 1993: Intel präsentiert den Pentium (3,1 Mio. Transistoren, 64 Bit, Cache erstmals eingebaut). Um den Clonern eins auszuwischen, nennt Intel seinen neuen Chip nicht 80586. Im Fließkomma-Bereich ist er dreimal so schnell wie ein 486er.
März 1994: Cyrix beginnt Upgrade-Prozessoren herzustellen, der 386er-PC zu 50 Prozent mehr Leistung verhelfen soll. Nexgen enthüllt auf der CeBit einen Prozessor der fünften Generation.
August 1994: IBM und Nexgen beschließen ein Produktionsabkommen.
September 1994: Nexgen stellt den Nx586 mit Pentium-Leistung vor,der aber sich aber nicht am Markt behaupten kann, da er keinen Coprozessor besitzt und nicht Pin-kompatibel zum Pentium ist.
November 1994: Schwerer Rückschlag für Intel: Der berühmte Pentium-Bug in der Fließkomma-Einheit (Auf der CeBit `95 werden T-Shirts mit der Aufschrift „Error Inside“ verkauft). Intel bietet einen kostenlosen Prozessoraustausch an.
März 1995: Auf der CeBit stellt Intel eine 120 MHz-Version des Pentium vor.
Juni 1995: Cyrix bringt einen 133 MHz-486er mit 16 KB Cache auf den Markt. Er ist schneller als ein P75, braucht aber weniger Strom. Der Pentium taktet nun mit 133 MHz, AMD stellt einen 486DX4 mit 120 MHz her.
Oktober 1995: Nexgen liefert erste Modelle der Nx586 mit 120 MHz aus und präsentiert gleichzeitig den Nx686 mit 48 KB Cache und einer internen Taktrate von 180 MHz. AMD, die mit der Entwicklung eines eigenen Microcodes nicht weiterkommen, übernehmen Nexgen.
November 1995: Der Pentium Pro (200 MHz interner Takt, 5,5 Mio. Transitoren, L2-Cache integriert) ist zwar abwärtskompatibel, unter Win95 ist er dem Pentium jedoch klar unterlegen, da er auf 32-Bit- Operationen optimiert ist. Windows 95 arbeitet aber zum Großteil noch mit 16-Bit-Befehlsfolgen.
Dezember 1995: Cyrix stellt zusammen mit IBM und SGS Thomson den 6x86 vor (Codename M1, Pin- kompatibel zum Pentium Sockel 7, 100 MHz intern, 50 MHz extern, 16 KB interner Cache). Unter bestimmten Bedingungen arbeitet er mindestens so schnell wie ein Pentium 100, zum Teil sogar schneller als der Pentium 133 und der Pentium Pro.
Februar 1996: AMD präsentiert den Am5x86. Der 486DX-Prozessor taktet intern mit 133 MHz (extern: 33 MHz). Intels Antwort: Die Preise des P100 und P120 fallen um bis zu 40 Prozent.
März 1996: IBM/Cyrix bringen den 6x86 als PR133+ (100/50 MHz), PR150+ (120/60 MHz) und als PR166+ (133/66 MHz) auf den Markt. Laut Tests sind sie trotz niedrigerer Taktrate schneller als die Intel-Originale. AMD präsentiert den K5PR75 (75 MHz) und bald darauf den K5PR100. Alle Prozessoren sind Pin-kompatibel.
Juni 1996: Der Pentium 200 kommt auf den Markt.
Juli 1996: Als Reaktion auf den K5 erklärt Intel seinen P100 als Auslaufmodell.
September 1996: IBM/Cyrix bringen den neuen PR200+ auf den Markt. Er erweist sich als leistungsfähiger als der Pentium 200 von Intel. Der PR200+ taktet intern mit 150 MHz (extern: 50 MHz). Durch den hohen externen Takt benötigt er ein spezielles Motherboard. Im Fließkommabereich liegen die 6x86-Prozessoren jedoch hinter dem Pentium.
Dezember 1996: AMD stellt den K5PR133 vor.
Januar 1997: Die Auslieferung des K5PR166 beginnt. Er taktet intern mit 115,5 und extern mit 66 MHz. Intels Pentium MMX 4,5 Mio. Transistoren, 32 KB Cache, Stromversorgung des Kerns mit 2,8 V, alle anderen Teile mit 3,3 V) wurde erweitert um 57 neue Befehle für den Multimedia-Bereich. Insgesamt soll er um 10 bis 15% schneller sein, bei Mm-Anwendungen sogar bis 87% (laut Intel).
April 1997: AMDs Antwort auf den MMX heißt K6 (64 KB Cache intern). Er hat eine MMX- Erweiterung (gen. 3DNow!), basierend auf dem Nexgen Nx6x86. Außer bei Fließkomma-ber. ist er dem MMX weit überlegen. Erhältlich ist er zunächst mit 166 und 200 MHz internen Takt.
Mai 1997: Intels PII (Codename Klamath, 7,5 Mio.Transistoren, 32 KB Cache intern) kommt auf den Markt. Taktraten bis 300 MHz sind erhältlich. Der externe Cache von 512 KB ist im Prozessor- gehäuse untergebracht. Für ihn wurde auch ein neuer Steckplatz entwickelt, Slot 1.
Juni 1997: Intel fertigt nun auch Pentiums mit bis zu 233 MHz hohen Taktraten. Cyrix stellt einen MMX- fähigen Prozessor (6x86MX, Codename M2) her. Auch er passt in den Sockel 7.
August 1997: Durch die starke Konkurrenz senkt Intel den Preis des PII mit 300 MHz um 57%. Der amerikanische Chip-Hersteller Natsemi (National Semiconductor) übernimmt Cyrix.
Sommer 1998: Intel präsentiert den Celeron (Verzicht auf L2-Cache).
1999: Vorstellung des PIII, der auf dem Kern des P Pro basiert. Er enthält Streaming SIMD Extensions (SSE), deren Nutzen bei rechenintensive Anwendungen liegt, die u.U. schneller laufen.
AMD stellt im Sommer den 500-MHz-Athlon-Prozessor (früherer Codename K7) vor, der in den meisten anderen Einsatzgebieten schneller als Intel- Prozessoren ist. Im Oktober eröffnet AMD ein Werk in Dresden. Dort sollen bald die neuen Athlons mit 1 GHz und mehr vom Band laufen. Intel bietet Paroli: Ein optimierter Pentium III mit dem Codenamen Coppermine folgt. Bei gleicher Taktfrequenz ist er wieder on par im Bereich der Business-Software. Geschlagen bleibt Intel weiterhin in der FPU-Leistung. Solche Floating-Point-Anwendungen kommen im wesentlichen im Profibereich (Workstations mit CAD- und Grafiksoftware) zum Einsatz.
Im Folgenden wird beschrieben, was allen x86-Prozessoren gemeinsam ist:
Auf den Adressbus werden Speicheradressen gelegt, deren Inhalte dann über den Datenbus übertragen werden. Die Breite des Datenbusses sagt nichts über die Verarbeitungsbreite des Prozessors aus, sondern nur wie viel Bytes auf einmal transportiert werden. Allgemein gilt: Je größer der Datenbus, desto schneller der Prozessor. Deswegen verfügen 32 Bit Prozessoren von Intel seit dem Pentium über einen 64 Bit Datenbus, der Datenbus ist hier also größer als die Verarbeitungsbreite des Prozessors. Ein großer Datenbus erlaubt es, mehr Daten auf einmal holen zu können; das kompensiert, dass der Arbeitsspeicher langsamer ist als der Prozessor.
Der Steuerbus funktioniert ähnlich. Er ist für die Steuerung von angeschlossenen Geräten zuständig, z.B. den Drucker oder den Monitor.
Die ALUs (Arithmetical/ Logical Unit) führen Ganzzahl- und Boolsche Operationen durch.
Für die gesamten Abläufe im Prozessor sorgt die Steuereinheit. Sie decodiert die einkommenden Daten, um festzustellen welche Befehle sie enthalten, regelt die interne Kommunikation und verändert nach Ausführung die Speicheradresse des aktuell auszuführenden Programms (Programmzähler).
Register sind Zwischenspeicher auf dem Prozessor zur Speicherung von Rechenergebnissen. Neben den Registern,die man als Programmierer benutzen kann, gibt es oft weitere die man direkt nicht bearbeiten kann wie den Programmzähler oder den Stackpointer, der einen Zwischenspeicher verwaltet. Im allgemeinen kann man von Registern nie genug haben, doch dazu mehr im folgenden Absatz.
Jeder Prozessor hat eine Anzahl sehr einfacher Befehle, die typisch für ihn und nicht auf andere Prozessoren übertragbar sind. So gibt es nicht eine Maschinensprache, sondern eine für Power PC, eine für Pentium und eine für Alpha-Prozessoren. Die Sprache hängt ab von der Architektur der Prozessoren.
Stellen wir uns vor, wir würden einen Prozessor bauen. Der benötigte (nach erstem Überschlag) 50 bis 70 Befehle. Diese könnten wir bequem in einem Byte (256 Zustrände) codieren. Doch so einfach geht das nicht. Manche Befehle benötigen Operanden, z.B. Increment (Registernumer?). Man wird also mit einem Byte nicht hinkommen, selbst wenn man von nur 4 Registern ausgeht (man könnte z.B. 4 Increment-Operationen ohne Operanden definieren). Also braucht man ein zweites Byte zur Codierung. Zum einen wäre dadurch der Code länger, zum andern dauert das Dekodieren von 2 Byte natürlich länger als von einem Byte.
Es gibt nun zwei Ansätze, dem zu begegnen. Beim CISC Ansatz (Complex Instruction Set Computer) versucht man mit weniger Registern auszukommen dafür mächte Befehle zu benutzen und oft spezialisierte Register. Dies trat schon bei 8 Bittern wie dem Z80 auf, der mit einem Befehl einen ganzen Speicherblock verschieben kann. Selten gebrauchte Operationen versucht man in 2 Byte zu kodieren, die häufigen dagegen in einem (Abkehr vom Operanden-Byte). Die Länge des Codes ist damit variabel und schwankte schon bei einem 8 Bit-System zwischen einem und 5 Byte.
Bei RISC (R= Reduced) sagt man sich dagegen: Wenn ich nicht alle Befehle in einem Byte codieren kann, dann wenigstens mit 2 Byte, indem ich das zusätzliche Byte nutze, um erheblich mehr Register anzusprechen. RISC Prozessoren haben daher oft sehr viele Register auf dem Chip - 32,64 oder gar 128 und alle sind gleichberechtigt. Es gibt nur die einfacheren Maschinenbefehle, nicht die Superbefehle von CISC. Dem Nachteil von längerem Code versucht man mit einem einheitlichen Format zu begegnen. Bei unserem Papierprozessor z.B. könnte man sagen: Alle Befehle, die mit Werten oder Adressen zu tun haben, werden in einem Byte kodiert, die nächsten 3 Byte entfallen dann auf die Adresse/ Daten und alle anderen Befehle werden in 2 Byte kodiert, dann entfallen die Bytes 3 und 4 auf jeweils die Nummer von einem von 256 Registern. Alle Befehle waren dann 32 Bits lang und man könnte 256 Register nutzen. Dafür verschwendet man Platz, denn bei CISC gibt es variable Befehlslängen, z.B. benötigt nicht jeder Befehl zwei Operanden, so das bei Registerbefehlen das 4. Byte oft unbenutzt wäre.
RISC entstand Mitte der 80er Jahre als Bewegung aus zahlreichen Universitätsinstituten heraus und wurde von Hardwareherstellern aufgegriffen, die in der Geschwindigkeit mit den Intel Prozessoren mithalten wollten, aber kein Geld besaßen, um solch komplexe Prozessoren zu fertigen.
Die ersten Prozessoren holten und schrieben alles direkt aus dem Speicher, der damals noch schneller als der Prozessor war. Beim 8086 wurde ein kleiner Zwischenspeicher eingeführt, der sogenannte Prefetch Queue, der linear arbeitet, d.h. wenn z.B. gerade die Adresse 4048 bearbeitet wird, liest er schon die Adresse 4049 ein. Da Programme normalerweise linear abgearbeitet werden, ist das auch sinnvoll. Wenn allerdings der Prozessor Daten braucht, die etwas weiter entfernt sind oder eine Verzweigung im Code kommt, dann nützt dieser Zwischenspeicher nichts und es dauert länger, ihn wieder neu zu füllen, als wenn man direkt auf den Speicher zugreift. Im Mittel gibt es jedoch einen deutlichen Performancegewinn.
Weiterhin dauerte das Schreiben auf den Speicher länger als das Lesen, außerdem haben Hochsprachenprogramme (Hochsprache= Sprache mit komplexen Prozeduren, zum Beispiel Pascal – im Gegensatz zu Maschinensprachen wie z.B. Assember) sehr oft Befehle, bei denen die Daten geholt werden, die gerade erst gespeichert wurden. Damit der 8088 nun nicht die veralteten Daten aus der Prefetch-Qeue holte, hatte er einen kleinen Schreibpuffer.
Der 80286 verfügte um erheblich längere Prefetch Queues und größere Schreibpuffer. Die Performancesteigerung gelang vor allem aber durch schnellere Befehlsausführung. Mit dem 386 kam nun eine erhebliche Änderung im Aufbau des Prozessors. Er wurde zu einem 32-Bit Prozessor, doch dazu später mehr. Der 386 war aber vor allem der erste Prozessor, der schneller als das RAM war. Damit nun der 386 überhaupt schneller als ein 286 war, musste man dies ausgleichen können und führte das Konzept des Caches ein, der damals noch separat auf der Hauptplatine untergebracht war. Der Prozessor selbst greift zuerst auf den Cache zu. Dieser speichert den Code vom Hauptspeicher zwischen und hat eine Zugriffszeit, die den Prozessor nicht ausbremst. Der Cache wird von einem Teil des Prozessors, dem Cachecontroller verwaltet. Er bündelt jeweils 16 oder 32 Bytes zu einer "Cacheline". Wenn der Prozessor neue Daten braucht, die nicht im Cache stehen, so muss der Cachecontroller diese vom Hauptspeicher laden. Dazu muss er entscheiden, welche Cachelines am längsten nicht benutzt wurden. Dazu hat er eine Indextabelle in der jeweils steht, welche Cacheline zu welcher Adresse gehört.
Mit dem 486 wurde der Cache in den Prozessor integriert und L1 Cache genannt, ein zweiter Cache auf der Hauptplatine wurde zum L2 Cache. Das Prinzip: Sind die Daten nicht im kleinen aber schnellen L1 Cache, so sind sie vielleicht im größeren und etwas langsameren L2 Cache, und erst dann muss man auf den Speicher zugreifen. Bei einigen Designs wie dem K6-III oder Alpha gibt es sogar L3 Caches mit bis zu 2 MB Größe.
Die Verwaltung von Caches, sowie ihr schneller Zugriff ist heute essentiell für die Performance eines Prozessors. Ein Großteil der Entwicklungszeit und Chipfläche geht heute auf die Optimierung der Caches drauf. Was der Cache ausmacht, kann man leicht selbst ausprobieren. Man kann im BIOS nämlich diese ausschalten. Macht man das, so ist auch der neueste Pentium 4 nicht mehr viel schneller als ein langsamer 486 er.
Die Memory Management Unit (MMU), die den Programmen vorgaukelt, sie hätten den gesamten Arbeitsspeicher (4 GB waren adressierbar) für sich alleine, wurde mit dem 386 eingeführt. Die MMU mappte diese dann im realen Speicher oder, wenn dieser nicht reichte, informierte der Prozessor das Betriebsystem, das er nun den Speicher von Programm x gerade braucht und dieses doch den Inhalt mal auf die Festplatte auslagern sollte. Der Speicher wurde dabei in kleine Scheiben von 4 KB oder 4 MB aufgeteilt und jeweils die Belegung von einer 4 KB-Scheibe in einer Tabelle gespeichert.
Mit dem Pentium-Pro (P6) und den auf seiner Architektur aufbauenden Modellen Pentium II und III wurde dieses Speichermanagment verbessert, indem man nun nicht nur 4 MB und 4 KB große Seiten ansprechen konnte, sondern jede Zweierpotenz, der virtuelle Adressraum von 4 auf 64 Gigabyte erhöht. Alle Windows Varianten bleiben aber noch immer im 4 Gigabyte Rahmen. Es macht also keinen Sinn einen Windows 2000 Server mit mehr als 4 GB Speicher auszustatten.
Um den 486 schneller zu machen, führte Intel je zwei paralelle ALUs und FPUs ein. Allerdings hatte sich der Maschinencode nicht geändert, man konnte also nicht entscheiden, welche Einheit von beiden benutzt werden sollte. Außerdem waren die Einheiten nicht unabhängig voneinander: Das langsame blockierte das schnellere. Dieser Missstand wurde erst mit dem P2 behoben, bei dem die Anzahl der Einheiten auch auf 3 erhöht wurde.
Eine Pipeline holt bei jedem Takt ein Byte oder mehrere aus dem Speicher. Dann beginnt bei jedem Takt ein weiterer Schritt der Ausführung eines Befehls. Benötigt ein Befehl 5 Takte zur Ausführung, so kann man mit einer fünfstufigen Pipeline pro Takt einen Befehl ausführen. Man kann also die Geschwindigkeit der Ausführung steigern - allerdings nur solange wie linear abgearbeitet wird. Verzweigt ein Programm, so sind alle Befehle in der Pipeline ungültig und es dauert lange, bis diese wieder gefüllt ist und wieder schnell arbeitet. Man nennt dies auch einen Pipeline stall. Dies wurde beim beim neuen Design des Pentium-Pro verhängnisvoll. Er bekam einen Pipeline Stall wenn man in ein 16 Bit Register schrieb und kurz darauf einen 8 Bit wert aus einer Hälfte des Registers auslas. Intel ging beim Design davon aus, das die Ankündigung von Microsoft stimmte, das neue Windows 95 wäre ein 32 Bit Betriebsystem und maß diesen in Windows 3.1 oft verwendeten Befehlsfolgen keine Bedeutung zu. Da Windows 95 jedoch noch voller 16 Bit Treiber war, war ein Pentium-Pro 166 plötzlich nur noch so schnell wie ein Pentium 120.
Intel hat bei den Designs die Pipeline immer mehr verlängert : Von 5 Stufen beim 486 über 13 Stufen beim Pentium II/III zu 20 Stufen beim Pentium 4. Das Problem der Pipeline stalls wird so natürlich problematischer. Daher führte Intel ab dem P6 einen Mechanismus ein, der zuerst unter Branch Execution Table und bei dem P4 als Trace Execution Cache firmiert. Der Prozessor schaut bei den folgenden Adressen nach, ob diese Sprünge enthalten und versucht die Wahrscheinlichkeit, dass dies der Fall ist, "vorauszuahnen" und merkt sich dann die folgenden Daten und holt sie aus dem Speicher. Man nennt dies auch spekulative Ausführung. Ein Vorteil von langen Pipelines ist, dass pro Stufe weniger zu tun ist - man braucht also pro Stufe weniger Zeit und kann so die Taktfrequenz steigern.
Beim P-Pro wurden die Pipelines der einzelnen Einheiten auch voneinander entkoppelt, allerdings wird dies Intel beim ersten 64 Bitter "Itanium" wieder zurücknehmen.
Seit dem 8086 hatten alle Prozessoren immer die gleiche Anzahl an Registern. Diese wurden zwar mit dem 386 er auf 32 Bit verbreitert, doch die Anzahl blieb. Dagegen wiesen neue Prozessoren wie Alpha 32 oder gar 64 Register auf. Mit der MMX-Version des Pentium gab es eine erste Erweiterung, jedoch mehr eine Marketing-Maßnahme als eine sinnvolle Erweiterung. Bei der MMX-Erweiterung können die Flieskommaeinheiten anstatt Flieskommarechnungen auch mehrere einfache Integer Berechnungen mit 8 oder 16 Bit parallel durchführen. Praktisch nutzbar war dies in den seltensten fällen. Mit dem Pentium II wurde dies zur leistungsfähigeren SSE Einheit erweitert, die nun nicht die Flieskommaregister benutzt sondern eigene 64 Bit Register, mit dem Pentium 4 werden diese auf 128 Bit erweitert.
Dies bringt einen Performancegewinn bei allen Operationen, bei denen mehrere Werte simultan denselben Rechnungen unterzogen werden wie z.B. JPEG-Codierung / Dekodierung. Bei der normalen Wald- und Wiesen-Applikation jedoch eher nicht. Intel plant daher für die kommende 64 Bit Architektur einen Systemschnitt und für den 64 Bit Modus eine neue Architektur mit RISC Befehlen, 128 Registern, so wie andere Firmen schon längst den Schritt zu RISC getan haben wie beim Alpha oder Power PC Prozessor.
Ein 8086 hat 8 für den Programmierer freie Register. Das ist sehr wenig. Anstatt nun in einem Register einen Wert zu berechnen und zu warten, bis das Ergebnis im Arbeitsspeicher abgespeichert ist (das dauert), und man den Register überschreiben kann, kann man einfach ein anderes Register zu diesem erklären und schon weitermachen.
Der Pentium 4 hat so 128 interne Register, also 16 mal mehr als der Programmierer direkt sehen kann. Beim Sledgehammer - dem ersten 64 Bit Prozessor von AMD geht man einen anderen Weg und verdoppelt im 64 Bit Modus die für den Programmierer nutzbaren Register auf je 16 Flieskomma und Integer Register.
Heimlich hat Intel auch dies schon längst getan. Mit dem Pentium hat Intel den Prozessorkern auf eine RISC Einheit umgestellt. Seitdem zerlegt der Prozessor seine ankommenden Befehle in einfachere RISC Operationen und mappt die 14 80x86 Register auf 32 interne RISC Register um. Dies machen auch die Konkurrenten Cyrix und AMD, weshalb die Prozessoren nicht mehr mit den Taktfrequenzen vergleichbar sind, da jeder RISC Kern bestimmte Befehle besser ausführt als ein Konkurrenzprozessor, der dafür andere Stärken hat. Beim Pentium 4 werden anders als beim Pentium II/III die fertig übersetzten Befehle im L1 Cache gesammelt.
So ist ein Pentium II/III heute nichts anderes als ein komplexer Emulator, der so tut als wäre er ein 386 er. Erstaunlich ist, dass es Intel damit zwar nicht gelingt, den schnellsten Prozessor zu bauen, aber doch in der Oberliga mitzuspielen. Doch einen Preis muss Intel aufbringen: Es gelingt nur mit einem sehr komplexen Chip (Intels Pentium 4 hat 42 Millionen Transistoren, der schnellere Alpha 21264 dagegen nur 15 Mio.) und hohen Taktfrequenzen (1.4 MHz für die gleiche Performance die der Alpha bei 700 MHz erreicht). Wenn man allerdings durch enorme Stückzahlen die Serienkosten senken kann und die Entwicklungskosten umlegen kann, spielt dies keine Rolle. Dagegen musste die Konkurrenz bis auf AMD die Segel streichen.
Doch was hat der Benutzer, der Programmierer davon ? Er sieht 8 Register, nicht 128. Er sieht eine ALU nicht 4 und muss durch trickreiche Umstellungen des Codes dafür sorgen, dass diese mit voller Geschwindigkeit arbeiten. Daher spricht Intel auch immer vom optimierten Code. Das Dumme ist nur, es gibt nicht den optimierten Code. Ein optimierter Code für den Athlon ist ein anderer als der für den Pentium III und wieder ein anderer für den Pentium 4. So ist der Pentium 4 bei 1.4 GHz langsamer bei SSE Befehlen als ein Pentium III - dieser hat zwei SSE, der P4 nur eine, weshalb Code der abwechselnd zwei SSE ansprechen will langsamer ist.
2001 kommt auch bei Intel der Einstieg in die 64-Bit Generation, die andere Firmen wie Compaq oder MIPS schon vor Jahren vollzogen haben. Man kann spekulieren, ob es der bleibende Erfolg der 32-Bit x86 Architektur ist oder die nur zaghaften Bestrebungen von MS, ihr 32 Bit Betriebssystem Windows NT auf 64 Bit zu erweitern, welche die Entwicklung so lange hinausgezögert haben. Aber Intel ist zum ersten mal gewillt, einen Schnit zu machen. der neue Prozessor hat einen Kompabiltätsmodus in dem bisheriger x86 Code weiter funktioniert - allerdings langsamer als auf einem derzeitigen Pentium 4. Neu ist ein neuer 64 Modus mit einer neuen Architektur: RISC Kern mit konstanten 41 Bit Befehlslängen, 128 Registern. Um beides realisieren zu können, hat man Abstriche bei den vielen Features gemacht. Die 4 ALU's und 2 FPU haben z.B. keine Möglichkeiten mehr, Abhängigkeiten zu erkennen und Befehle umzugruppieren - dies hat Intel auf den Compiler ausgelagert, der je 4 32-Bit Operationen zu einem 128 Bit Wort bündet und die letzten 5 Bits zur Speicherung der Abhängigkeiten dieser und der folgenden Befehle nutzt. Damit steht diese schon für den Prozessor fest und die gesamte Logik zum Umgruppieren ist überflüssig. Anders hätte man den 64 Bit-Prozessor samt 32 Bit x86 Kern nicht in 25 Millionen Transistoren fertigen können - zum Vergleich der aktuelle Pentium 4 hat 42 Millionen.
Zukünftige Neuentwicklungen
Um die Geschwindigkeit zu steigern, gibt es verschiedene Möglichkeiten. Im Intel Lager hat man das Problem, das die parallelen Einheiten nur wenig genutzt werden. Das liegt an verschiedenen Faktoren, zum einen an der veralteten Architektur, bei der Maschinencode in einfacheren RISC Code umgesetzt wird, wobei der Programmierer aber nicht 4 ALU's ansprechen kann sondern nur eine und nicht 128 Register sondern nur 8. Hier ist es das Ziel, dass der Code die Einheiten besser ausnutzt. Beim Itanium z.B. legt der Compiler, der ja den Sourcecode kennt, fest, wie Befehle voneinander abhängig sind. Funktioniert dies, so vereinfacht dies die Logik des Prozessors und erhöht die Geschwindigkeit.
Ein anderer Weg ist ganz einfach von vornherein unabhängige Prozesse zu nehmen - und die gibt es schon heute genug. Jedes Betriebssystem hat, selbst wenn gar nichts passiert, einige Dutzend von einander unabhängigen Threads, also unabhängigen Programmen, und wenn ein Prozessor für jeden Thread eigene Register hat, so können diese parallel ausgeführt werden. Diesen Ansatz verfolgt z.B. z.Zt. Compaq bei der Prozesssorentwicklung. Entscheidend ist, das man Threads, die nichts zu tun haben, schnell durch andere ersetzen kann, die Rechenzeit benötigen, d.h. das vor allem das Wechseln der Register schnell geht. Platz genug für viele Register ist heute schon vorhanden.
Wenn in diesem Artikel andere Prozessoren nur am Rande erwähnt werden, so nicht weil sie unbedeutend sind oder Intel die Krone in der Prozessortechnik hat. Im Gegenteil ! Andere Firmen mit weniger Marktanteil konnten schon in den späten 80er oder Anfang der 90er Jahren reine RISC Systeme entwickeln. Motorola - Intels größter Konkurrent zu 16 Bit Zeiten - hat schon 1993 den Power PC Prozessor entwickelt und die 68K Linie auslaufen lassen. MIPS und Digital (heute Compaq) konnten ohne Kompabilitätsrücksicht reine RISC Prozessoren entwickeln. Doch gerade weil Intel mit allen Tricks die Systemleistung ihrer 20 Jahre alten Architektur noch steigern konnte sind sie ein gutes Beispiel für die Technologien in modernen Prozessoren.
Mnemonic ODITSZAPC Description
AAA ?---??*?* ASCII Adjust for Add in AX
AAD ?---**?*? ASCII Adjust for Divide in AX
AAM ?---**?*? ASCII Adjust for Multiply in AX
AAS ?---??*?* ASCII Adjust for Subtract in AX
ADC d,s *---***** Add with Carry
ADD d,s *---***** Add
AND d,s *---**?** Logical AND
CALL a --------- Call
CBW --------- Convert Byte to Word in AX
CLC --------0 Clear Carry
CLD -0------- Clear Direction
CLI --0------ Clear Interrupt
CMC --------* Complement Carry
CMP d,s *---***** Compare
CMPS *---***** Compare memory at SI and DI
CWD --------- Convert Word to Double in AX,DX
DAA ?---***** Decimal Adjust for Add in AX
DAS ?---***** Decimal Adjust for Subtract in AX
DEC d *---****- Decrement
DIV s ?---????? Divide (unsigned) in AX(,DX)
ESC s --------- Escape (to external device)
HLT --------- Halt
IDIV s ?---????? Divide (signed) in AX(,DX)
IMUL s *---????* Multiply (signed) in AX(,DX)
IN d,p --------- Input
INC d *---****- Increment
INT --00----- Interrupt
INTO --**----- Interrupt on Overflow
IRET ********* Interrupt Return
JB/JNAE a --------- Jump on Below/Not Above or Equal
JBE/JNA a --------- Jump on Below or Equal/Not Above
JCXZ a --------- Jump on CX Zero
JE/JZ a --------- Jump on Equal/Zero
JL/JNGE a --------- Jump on Less/Not Greater or Equal
JLE/JNG a --------- Jump on Less or Equal/Not Greater
JMP a --------- Unconditional Jump
JNB/JAE a --------- Jump on Not Below/Above or Equal
JNBE/JA a --------- Jump on Not Below or Equal/Above
JNE/JNZ a --------- Jump on Not Equal/Not Zero
JNL/JGE a --------- Jump on Not Less/Greater or Equal
JNLE/JG a --------- Jump on Not Less or Equal/Greater
JNO a --------- Jump on Not Overflow
JNP/JPO a --------- Jump on Not Parity/Parity Odd
JNS a --------- Jump on Not Sign
JO a --------- Jump on Overflow
JP/JPE a --------- Jump on Parity/Parity Even
JS a --------- Jump on Sign
LAHF --------- Load AH with 8080 Flags
LDS r,s --------- Load pointer to DS
LEA r,s --------- Load EA to register
LES r,s --------- Load pointer to ES
LOCK --------- Bus Lock prefix
LODS --------- Load memory at SI into AX
LOOP a --------- Loop CX times
LOOPNZ/LOOPNE a --------- Loop while Not Zero/Not Equal
LOOPZ/LOOPE a --------- Loop while Zero/Equal
MOV d,s --------- Move
MOVS --------- Move memory at SI to DI
MUL s *---????* Multiply (unsigned) in AX(,DX)
NEG d *---***** Negate
NOP --------- No Operation (= XCHG AX,AX)
NOT d --------- Logical NOT
OR d,s *---**?** Logical inclusive OR
OUT p,s --------- Output
POP d --------- Pop
POPF ********* Pop Flags
PUSH s --------- Push
PUSHF --------- Push Flags
RCL d,c *-------* Rotate through Carry Left
RCR d,c *-------* Rotate through Carry Right
REP/REPNE/REPNZ --------- Repeat/Repeat Not Equal/Not Zero
REPE/REPZ --------- Repeat Equal/Zero
RET (s) --------- Return from call
ROL d,c -------- Rotate Left
ROR d,c *-------* Rotate Right
SAHF ----***** Store AH into 8080 Flags
SAR d,c *---**?** Shift Arithmetic Right
SBB d,s *---***** Subtract with Borrow
SCAS *---***** Scan memory at DI compared to AX
SEG r --------- Segment register
SHL/SAL d,c *---**?** Shift logical/Arithmetic Left
SHR d,c *---**?** Shift logical Right
STC --------1 Set Carry
STD -0------- Set Direction
STI --0------ Set Interrupt
STOS --------- Store AX into memory at DI
SUB d,s *---***** Subtract
TEST d,s *---**?** AND function to flags
WAIT --------- Wait
XCHG r(,d) --------- Exchange
XLAT --------- Translate byte to AL
XOR d,s *---**?** Logical Exclusive OR
-*01? Unaff/affected/reset/set/unknown
OF O Overflow Flag (Bit 11)
DF D Direction Flag (Bit 10)
IF I Interrupt enable Flag (Bit 9)
TF T Trap Flag (Bit 8)
SF S Sign Flag (Bit 7)
ZF Z Zero Flag (Bit 6)
AF A Auxilary carry Flag (Bit 4)
PF P Parity Flag (Bit 2)
CF C Carry Flag (Bit 0)
ALIGN Align to word boundary
ASSUME sr:sy(,...) Assume segment register name(s)
ASSUME NOTHING Remove all former assumptions
DB e(,...) Define Byte(s)
DBS e Define Byte Storage
DD e(,...) Define Double Word(s)
DDS e Define Double Word Storage
DW e(,...) Define Word(s)
DWS e Define Word Storage
EXT (sr:)sy(t) External(s)(t=ABS/BYTE/DWORD/FAR/NEAR/WORD)
LABEL t Label (t=BYTE/DWORD/FAR/NEAR/WORD)
PROC t Procedure(t=FAR/NEAR, default NEAR)
ABS Absolute value of operand
BYTE Byte type operation
DWORD Double Word operation
FAR IP and CS registers altered
HIGH High-order 8 bits of 16-bit value
LENGTH Number of basic units
LOW Low-order 8 bit of 16-bit value
NEAR Only IP register need be altered
OFFSET Offset portion of an address
PTR Create a variable or label
SEG Segment of address
SHORT One byte for a JMP operation
SIZE Number of bytes defined by statement
THIS Create a variable/label of specified type
TYPE Number of bytes in the unit defined
WORD Word operation
AX BX CX DX Accumulator/Base/Count/Data registers
AL BL CL DL Low byte of general registers
AH BH CH DH High byte of general registers
SP BP Stack/Base Pointer registers
SI DI Source/Destination Index registers
CS DS SS ES Code/Data/Stack/Extra Segment registers
IP Instruction Pointer register
a Address
c Count
d Destination
e Expression or string
p I/O port
r Register
s Source
sr Segment register (CS,DS,SS,ES)
sy Symbol
t Type of symbol
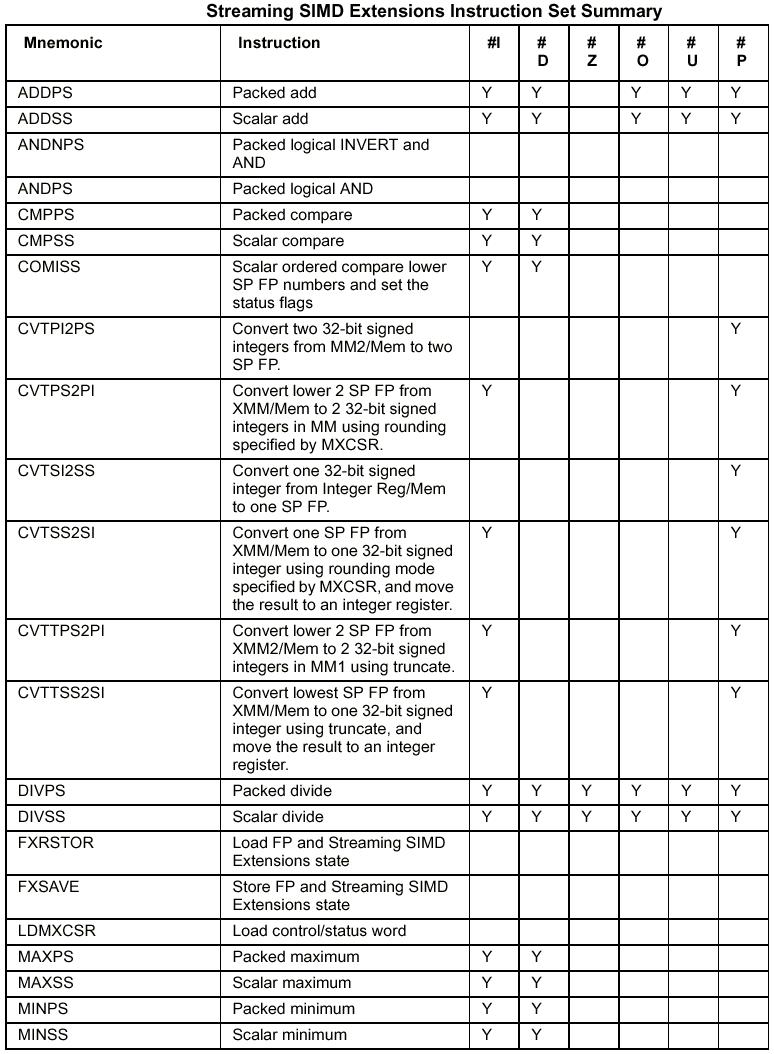
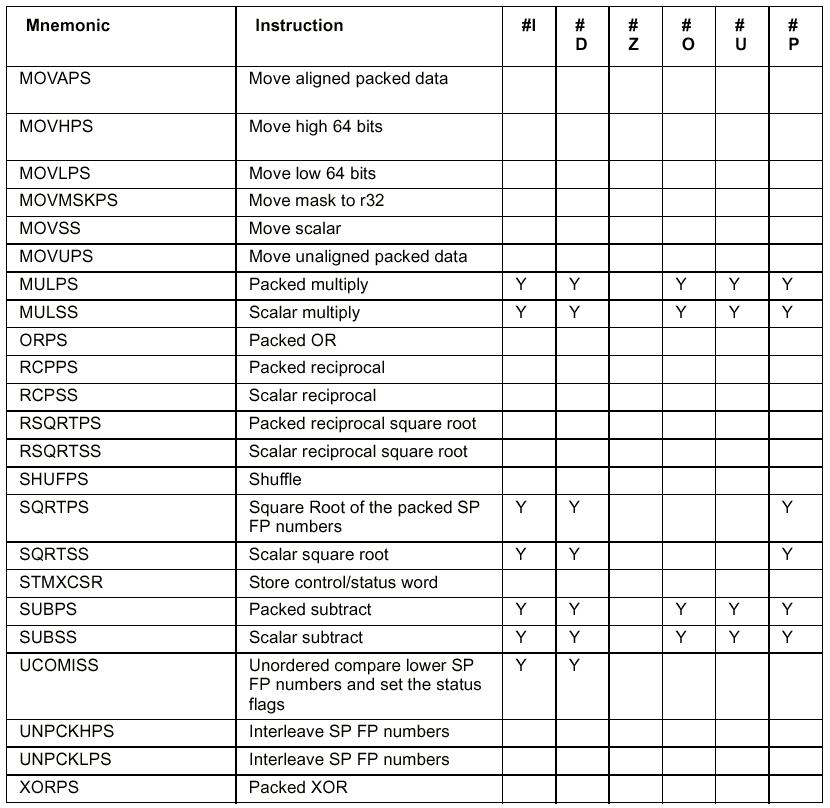
ISSE (zuerst bekannt als MMX2 oder KNI – Katmai (Codename des P3 während der Entwicklung) New Instructions) steht für Internet Screaming SIMD Extension und ist eine Sammlung von 72 zusatzlichen Befehlen für die verschiedensten Anwendungen. Wichtig ist eigentlich nur das zweite S in dieser Abk. . Das steht für SIMD und bedeutet Single Instruction Multiple Data, was soviel heißt wie, dass ein Befehl auf einen ganzen Satz Daten gleichzeitig angewendet werden kann. Dieses Prinzip fand sich auch schon bei MMX, dort konnten allerdings nur Ganzzahlen verarbeitet werden. ISSE verarbeitet jedoch auch Fließkommazahlen. ISSE will jedoch nicht , wie seinerzeit MMX, als Befehlssatz zur reinen Steigerung der Spieleperformance verstanden werden, sondern Intel betont auch den Nutzen für allgemeine Applikationen. Man kann ISSE in vier Befehlsgruppen einteilen:
MMX Befehle
Memory Screaming Instructions
Skalare Gleitkomma-Befehle
SIMD Gleitkomma-Instruktionen
Die MMX Befehle sind die verbesserten
Befehle aus den damaligen MMX Prozessoren und bewirken eine bessere
Leistung bei 3D-Spielen und z.B. bei der MPEG Kodierung.
Die Memory Screaming Instructions
sorgen für eine Beschleunigung des Datentransfers zwischen CPU,
Cache, RAM und AGP-Bus und verbessern so die Leistung von
Videoapplikationen und Spielen.
Die Skalaren Gleitkomma-Befehle und die SIMD Gleitkomma-Instuktionen sind um die neuen acht 128-Bit Register angeordnet bzw. arbeiten mit diesen neuen Registern.
Die SIMD Gleitkomma-Instruktionen finden ihren Einsatz bei der gleichförmigen Manipulation großen homogener Datenmengen, z.B. bei der Matrizenmultiplikation, wo riesige Zahlenberge abgearbeitet werden müssen. Matrizenmultiplikationen finden eine breite Anwendung bei der Koordinaten-transformation und werden überall eingesetzt, wo geometrische Objekte insbesondere im 3D-Raum manipuliert werden. Somit ergibt sich als typische Anwendung CAD, wo diese Einheit z.B. die Rotation oder Skalierung von dreidimensionalen Objekten übernehmen kann oder 3D-Beleuchtungsmodelle berechnet.
Die FPU des Pentium kann nicht mit den Prozessorregistern der CPU arbeiten und hat deshalb 8 eigene Register. Jedes ist 80 Bit breit, und zu jedem gehört ein 2-Bit Tag-field, welches zusätzliche Informationen über den Inhalt des Registers speichert. Die Tag-fields sind zusammengefaßt in dem 16-Bit breiten Tag-Register.
Auch bei normalisierten Zahlen ist das Vorkomma-bit der Mantisse hier immer enthalten, dadurch kann der Prozessor schneller mit diesen Zahlen arbeiten, da keine Umrechnung mehr erfolgen muß. Obwohl es möglich ist, Operationen auf 32-Bit oder 64-Bit Operanden anzuwenden, rechnet die FPU intern immer mit 80-Bit Genauigkeit.
Leider sind die FPU-Register nicht linear adressierbar, sondern haben einen stapelähnlichen Aufbau. Sie heißen ST(0)-ST(7), wobei ST(0) als Top of Stack oder kurz TOS bezeichnet wird. Jede Operation wird grundsätzlich auf dem TOS ausgeführt, wobei der 2. Operand der Operation jedes andere FPU-Register oder eine Speicherstelle sein kann. Wird ein Wert aus dem Speicher geladen (Ziel ist immer TOS), werden vorher automatisch ST(0)-ST(6) nach ST(1)-ST(7) kopiert (intern wird eigentlich nur die Nummer des TOS verändert). Sollte ST(7) dabei nicht leer sein, wird eine Exception ausgelöst.
Dieses Register wird nach jeder Operation mit neuen Werten belegt. Hier wird zum Beispiel die Nummer des Registers gespeichert, das momentan der TOS ist. Weiterhin werden Bits in Abhängigkeit von der ausgeführten Operation und deren Ergebnis gesetzt. Exception-Flags werden gesetzt, wenn ein Operand oder das Ergebnis nicht gültig waren. Die Bits C0-C3 sind dabei ähnlich dem Condition-code der CPU, und lassen sich in das Flagregister der CPU übertragen. Dies ist notwendig, da es keine Befehle gibt, die auf Condition-codes der FPU direkt reagieren können.
Das letzte wichtige Register der FPU ist das Control-Word-Register. In diesem kann man einige Bits festlegen, die direkt die Arbeitsweise der FPU beeinflussen.
Zu jedem Exception-Flag des Status-Words existiert hier ein Exception-Mask-Bit, durch das verändern eines solchen Bits legt man fest, ob bei Auftreten dieses Fehlers bei einer Operation tatsächlich eine Exception ausgelöst werden soll. Eine Exception wird also nur dann ausgelöst, wenn sowohl das Exception-Flag als auch das entsprechende Exception-Mask-Bit gesetzt sind. In den Feldern Rounding-Control und Precision-Control bestimmt man die Art der Rundung und die Genauigkeit von Rechenoperationen:
Der Befehlsumfang der Pentium-FPU
umfaßt folgende Arten von Operationen:
- data transfer
(Register laden, speichern, tauschen)
- arithmetic (Addition,
Subtraktion, Multiplikation, Division, Wurzel, Logarithmen,
Potenzierung, Trigonometrie...)
- compares (Vergleiche, um die
Condition-codes zu setzen)
- load constant (Laden von Konstanten
wie 0,1,pi...)
- control (Registerinhalte sichern oder
wiederherstellen, Initialisierung...)
Der Pentium hat 2 getrennte Pipes zur Ausführung von Befehlen, die U-Pipe und die V-Pipe. Zwei Befehle können in je einer Pipeline gleichzeitig ausgeführt werden, wenn sie von einander unabhängig sind. Leider sind durch die Stack-Struktur der Pentium-FPU unabhängige Paarungen von Befehlen nicht ohne weiteres möglich. Deshalb ermöglicht es die Struktur der FPU, das der fxch Befehl, welcher die Inhalte zweier FPU-Register vertauscht, abgearbeitet wird, ohne einen zusätzlichen Takt zu benötigen. Dies ermöglicht es, eine lineare Registerstruktur zu simulieren. Das folgende Beispiel zeigt die erhebliche Geschwindigkeitssteigerung, die man erreichen kann, obwohl die FPU noch mehr Befehle ausführt.
Quellen:
ivs.cs.uni-magdeburg.de/bs/lehre/wise9900/proro/vortrag/fpu/fpu.html
/vortrag/pentium/main.html
/vortrag/pentium_erw/isse.html
webhome1.ai-lab.fh-furtwangen.de/~bierig/pt/isse2.html
ftp.comlab.ox.ac.uk/pub/Cards/txt/8086.txt
www.htlwrn.ac.at/d95043/x86_cpus.htm
www.seitzweb.de/Interessen/Computer/Geschichte/CPUs.htm
www.de.tomshardware.com/cpu/99q4/991115/superg-01.html
www.home.knuut.de/Bernd.Leitenberger/rechnerarchitekturen.htm
cisc-risc.htm
www.informatik.tu-cottbus.de/~fsi/Skripte/proz-WS99/proz-5.pdf