![]()
Die schriftliche Version unserer Studienarbeit im Postscript-Format findet sich hier (3,7MB) und hier gezipt (188 KB).
Durch die steigende Komplexität und Integration im Chipdesign werden immer komplexere Ablaufsteuerungen erforderlich. Daher gewinnen endliche Automaten zur Modellierung in diesem Gebiet zunehmend an Bedeutung. Trotzdem fehlt es hier noch an geeigneten grafischen Entwicklungstools, insbesondere im Bereich Public Domain Software.
Außerdem entstand im Arbeitsbereich TECH der Universität Hamburg der Wunsch, den Studenten im Grundstudium die Grundlagen der Technischen Informatik durch praktische Beispiele näher zu bringen. So entstand die Idee ein Programm zu entwickeln, das beiden Anforderungen gerecht wird. JavaFSM ist also sowohl für Studenten zur Einführung, als auch für Entwickler zum praktischen Einsatz gedacht.
Als Programmmiersprache wurde die neue, objektorientierte Sprache Java von Sun Microsystems gewählt. Java bietet gegenüber herkömmlichen Programmiersprachen mehrere Vorteile:
| Java ist plattformunabhängig. Ein Java-Programm wird
von einem Compiler in plattfomunabhängigen Bytecode
übersetzt, der dann zur Laufzeit von einem Interpreter,
der Java Virtual Machine, ausgeführt wird. Die Virtual
Machine ist mittlerweile für alle gängigen Systeme
implementiert. Java ist objektorientiert. Bei der Objektorientierung stehen die Daten und deren Manipulation im Vordergrund, nicht die Prozeduren. Objekte können ihre Eigenschaften an andere Objekte vererben oder um weitere Eigenschaften ergänzt werden. Java bietet umfangreiche Klassen-bibliotheken, die neben Standard-Funktionen auch neue Bereiche, wie Netzwerk- und Datenbankzugriff abdecken. Da sich die Bibliotheken bereits beim Client im Java-Interpreter befinden, müssen diese nicht über das Netz geladen werden. |
 |
Neben Standalone-Applikationen bietet Java die Möglichkeit, Programme in HTML-Seiten einzubetten. Diese sogenannten Applets werden dann von der in den Browser integrierten Virtual Machine ausgeführt. Java-Applets sind daher über das World-Wide-Web weltweit zugänglich. Ein weiterer Vorteil von Applets ist, daß keine Installation notwendig ist. Auch Updates passieren durch einen einfachen Austausch der Klassen auf dem WWW-Server.
Durch die Plattformunabhängigkeit von Java und die Möglichkeit Applets in HTML-Seiten einbetten zu können, eignet sich Java besonders gut für den Einsatz in der Lehre, da hierdurch viele Leute erreicht werden können.
Referenzplattform für Java ist das Java Developers Kit (JDK) der Firma Sun.
Das JDK bietet mit dem Befehl javadoc die Möglichkeit an, aus dem Sourcecode und den Kommentaren automatisch eine Dokumentation der Klassen in HTML zu generieren. Die Javadoc-Dokumentation zu JavaFSM findet sich hier.
JavaFSM läßt sich sowohl als Applet, als auch als Applikation starten.
Grundsätzlich besteht JavaFSM aus drei Fenstern: in dem ersten ist das Schaltwerkmodell mit den Ein- und Ausgängen zu sehen. Hier kann ein Automaten-Name vergeben und der Schaltwerk-Typ festgelegt werden. Außerdem können die Ein- und Ausgänge hinzugefügt, geändert und gelöscht werden. Nach Eingabe des Automaten kann dieser hier simuliert werden. Dazu gibt es einen Takt- und einen Reset-Button. Im Delta-Schaltnetz ist der Automat sichtbar. Der aktuelle Zustand und die unter der momentanen Belegung aktivierte Transition sind rot markiert.
Im Editorfenster wird der Automat entworfen. Hier werden Zustände, Transitionen, sowie Übergangs- und Ausgabefunktionen eingegeben. Zusätzlich besteht die Möglichkeit einen Automaten mit Kommentaren zu versehen. Der Editor arbeitet Modus-orientiert. Über Buttons kann man jeweils den Modus wechseln. Es gibt 6 Modi: im Bewegen-Modus lassen sich Zustände verschieben. Außerdem können Transitionen und Zustände selektiert werden, um im Parameterfeld deren Eigenschaften (Name, Funktion, etc.) zu verändern (siehe auch Selektionsalgorithmus). Je nachdem, ob ein Moore- oder Mealy-Automat editiert wird, ändert sich das Parameterfeld der Zustände. Während jeder Output bei Moore feste Ausgabewerte hat, kann bei Mealy jeweils eine Funktion (über den Inputs) eingegeben werden. Auf diese Weise läßt sich das Lambda-Schaltnetz "simulieren", ohne das eine konkrete Zustandskodierung existiert.
Der Zustand-Modus fügt per Mausklick Zustände ein. Im Transition-Modus werden zwei Zustände jeweils durch Anklicken mit einer Transition verbunden. Die Transitionen werden als Pfeile zwischen zwei Zuständen dargestellt. Der Algorithmus zum Zeichnen der Pfeile wurde dem Programm JavaFIG in [He97] entnommen. Durch Anklicken im Lösch-Modus können Komponenten wieder entfernt werden. Den Startzustand legt man im Startzustand-Modus fest. Im Kommentar-Modus lassen sich auf der Zeichenfläche Kommentare einfügen. Da während der Simulation der Automat nicht verändert werden darf, wird das Editorfenster dabei automatisch geschlossen.
Das dritte Fenster mit dem Impulsdiagramm bietet die Möglichkeit, sich die Simulations-ergebnisse darstellen zu lassen. Dabei werden die folgenden Daten benötigt: die Zustands-folge (im Vektor "zustandsfolge" der Klasse FSM), die In- und Outputs (in den Vektoren "inputs" und "outputs" der Klasse FSM) und die Wertefolgen der In- und Outputs (im Vektor "taktfolge" der Klasse Signal für jeden In- und Output). Zu besseren Unterscheidung werden die Inputs blau und die Outputs rot in verschiedenen Farbabstufungen dargestellt.
Ein Problem ergab sich im Impulsdiagramm bei Mealy-Automaten. Hier können sich die Ausgangswerte auch zwischen den Takten ändern, wenn sich die Eingangswerte ändern. Hier haben wir sogenannte Zwischentakte eingeführt. Jede Änderung der Eingangswerte generiert so einen Zwischentakt. Zusätzlich wurde ein Vektor "taktfolge" in die Klasse FSM eingefügt, der für jeden echten Takt ein "true" enthält und für jeden Zwischentakt ein "false". Im Impulsdiagramm werden nun bei Mealy-Automaten sowohl echte als auch Zwischentakte angezeigt. Taktlinien und Beschriftung werden jedoch nur bei echten Takten eingefügt.
Zur Repräsentation und Verarbeitung endlicher Automaten wurde die Klasse FSM entworfen. Hier werden alle Daten des Automaten zusammengefaßt. Außerdem stellt die Klasse alle Grundfunktionen zum Bearbeiten zur Verfügung.
Die Basiskomponenten eines endlichen Automaten sind Zustände, Transitionen, Inputs und Outputs. Deren Eigenschaften sind in der folgenden Tabelle aufgelistet:
| Zustand | Transition | Input | Output |
|---|---|---|---|
|
|
|
|
Die dynamischen Werte der Simulation werden jeweils direkt bei dem entsprechenden Objekt gespeichert, d.h.
"Just-in-time-Parsing"
Die Berechnung von Übergangstabellen für den endlichen Automaten erfordert exponentiellen Rechenaufwand und zusätzlichen Speicher. Bei einer Änderung des Automaten müssen die Tabellen spätestens zur Simulation neu berechnet werden. Die in JavaFSM verwendete Alternative ist das "Just-in-time"-Parsen der jeweils benötigten Funktionen während der Simulation. Dabei werden nur Transitionen betrachtet, die vom aktuellen Zustand ausgehen.
Zur Berechnung der Übergangsbedingungen und der Ausgabefunktionen in den Zuständen dient die Klasse Parser, die die jeweilige Funktion als String übergeben bekommt.
Größerer Rechenaufwand (exponentiell) fällt nur beim Überprüfen von Automaten ("FSM testen"-Button im Editor) und beim Export nach KISS an, da hier sämtliche Funktionen mit allen möglichen Belegungen berechnet werden müssen.
Der Editor enthält eine Funktion, die es erlaubt, den Automaten auf syntaktische Fehler zu überprüfen.
Der "FSM-Tester" überprüft zunächst, ob überhaupt Zustände und Transitionen vorhanden sind, und ob einer der Zustände als Startzustand definiert wurde. Danach geht er alle möglichen Belegungen durch und stellt fest, ob jeweils genau eine Transition aktiviert ist. In einem Dialogfenster werden dabei Statusmeldungen und gegebenenfalls Fehler ausgegeben.
Die Selektion von Zuständen erfolgt einfach durch die Berechnung der Entfernung zwischen Zustandsmittelpunkt und Klickpunkt (siehe Abbildung). Um Transitionen zu selektieren, müßte eigentlich die Entfernung vom Klickpunkt zur Linie (Lot) berechnet werden. Eine einfachere Möglichkeit besteht im Vergleich der Entfernung beider Zustände mit der Summe der Entfernungen der Zustände zum Klickpunkt. Ist diese nur unwesentlich größer, dann wurde auf bzw. direkt neben die Transition geklickt:
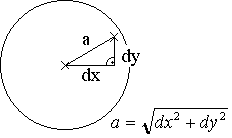 |
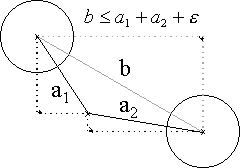 |
| Zustandsselektion | Transitionsselektion |
JavaFSM bietet die Möglichkeit, selbst entworfene Automaten zu speichern und wieder zu laden.
In der Applikation wird dabei über die Menüpunkte Laden und Speichern ein File-Requester geöffnet, über den sich eine Datei auswählen läßt.
Im Applet wird in einem Dialogfenster ein Name und ein Paßwort angegeben und der Automat unter diesem Namen auf dem Server abgelegt.
Eine FSM-Datei hat den folgenden Aufbau:
| [JavaFSM V1.0] | Header mit Versionsnummer |
| [Machine Type] | MEALY oder MOORE |
| [Name] | Kennzeichnet den Namens-Block |
| Name | gibt den Namen des Automaten an |
| [Inputs Anzahl] | Kennzeichnet den Input-Block, wobei Anzahl angibt wieviele Inputs es gibt |
| name,initial | Name und Startwert eines Inputs (jede Zeile enthält genau einen Input) |
| [Outputs Anzahl] | Kennzeichnet den Output-Block, wobei Anzahl angibt wieviele Outputs es gibt |
| name | Name eines Outputs (jede Zeile enthält genau einen Output) |
| [Zustaende Anzahl] | Kennzeichnet den Zustands-Block, wobei Anzahl angibt wieviele Zustände es gibt |
| name,xpos,ypos,isStart,output1_fkt... | Name, Position, isStart (boolean) und für jeden Output die Ausgabefunktion |
| [Transitionen Anzahl] | Kennzeichnet den Transitions-Block, wobei Anzahl angibt wieviele Transitionen es gibt |
| name1,name2,fkt | Namen der beiden Zustände und die Übergangsfunktion |
| [Kommentare Anzahl] | Kennzeichnet den Kommentar-Block, wobei Anzahl angibt wieviele Kommentare es gibt |
| xpos, ypos, Text | Position und Kommentar-Text (dieser kann "%10" für einen Zeilenumbruch enthalten) |
| [ENDE] | Markiert das Ende |
Beispiel:
[JavaFSM V1.0] [MOORE] [Name] Beispiel-Automat [Inputs 2] a,0 b,1 [Outputs 3] x y z [Zustaende 2] Zustand 1,58,129,true,0,1,0 Zustand 2,229,222,false,1,0,1 [Transitionen 4] Zustand 2,Zustand 1,b Zustand 1,Zustand 1,* Zustand 1,Zustand 2,a Zustand 2,Zustand 2,* [Kommentare 1] 10,10,Dies ist ein Beispielautomat [ENDE]
Ein Java Applet kann aus Sicherheitsgründen nicht auf das Filesystem des Rechners zugreifen. Eine Möglichkeit zur Speicherung von Automaten besteht darin, Text in einem Fenster auszugeben und diesen mittels Copy&Paste zu speichern. Diesen Weg gehen wir bei der Konvertierung des Automaten nach VHDL / KISS, damit der Anwender die Daten direkt weiterverarbeiten kann.
Das Versenden einer e-mail mit den Daten an den User stellt eine weitere Möglichkeit zur Datensicherung dar. Diese löst jedoch noch nicht das Problem des Ladens von Automaten.
Die Lösung, die wir zum Laden und Speichern von Automaten gewählt haben, liegt in einer Netzwerkverbindung zum Hostrechner. Statt einen eigenen Server in Java zu implementieren, bot sich die Verwendung des vorhandenen WWW-Servers an. Ein WWW-Server bietet mit dem CGI (Commin Gateway Interface) die Möglichkeit, Programme zu starten [He96]. Diese CGI-Programme werden über eine bestimmte URL aufgerufen. Sie können beispielsweise dynamisch HTML-Seiten generieren (z.B. Suchmaschinen).
Die Kommunkation zwischen Browser, Server und CGI-Programm läuft folgendermaßen ab: der Browser sendet eine Anfrage an den Server und erwartet darauf eine Antwort. Der Server startet daraufhin das in der Anfrage angegebene CGI-Programm, welches die Anfrage verarbeitet, die gewünschte Antwort generiert und über den Server an den Browser leitet.
Im Hypertext-Transfer-Protokol (HTTP) gibt es für Browser-Anfragen zwei Kommandos: mit dem GET-Kommando können Daten nur direkt in der URL versendet werden. Da eine URL jedoch in ihrer Länge beschränkt ist, reicht dies nicht immer aus. Mit dem POST-Kommando lassen sich dagegen beliebig große Datenmengen übertragen.
JavaFSM nutzt zum Laden und Speichern getrennte CGI-Programme. Beim Laden sendet das Applet als Parameter den Automaten-Namen und ein Paßwort. Das CGI-Programm sucht den angegebenen Automaten und überprüft das zugehörige Paßwort. Tritt kein Fehler auf, sendet es die Daten des Automaten an das Applet. Zum Speichern von Automaten sendet das Applet ebenfalls Name und Paßwort, gefolgt von den Daten. Sofern der Name noch nicht vergeben ist, bzw das Paßwort stimmt, schreibt das CGI-Programm Paßwort und Daten in ein File. Die Antwort an das Applet besteht aus einer Bestätigung bzw. einer Fehlermeldung.
Das Paßwort dient hauptsächlich zum Schutz vor ungewolltem Überschreiben durch andere. So kann nur der Designer des Automaten auf das File zugreifen.
Über Applet-Parameter können bestehende Automaten als Beispiele in das Menü mit aufgenommen und von dort geladen werden.
Weitere Literatur:
Der Parser wird benötigt, um die logischen Ausdrücken der Übergangsbedingungen und Ausgabefunktionen (nur bei Mealy) auszuwerten.
Basis-Einheiten eines Ausdrucks sind die Operatoren UND (&), ODER (|) und NICHT (!), die Namen der Inputs als Eingangsvariablen und die Werte 0 und 1, sowie Klammern. Die Grammatik des Parsers lautet:
Die Syntaxanalyse geschieht im Stil des rekursiven Abstiegs. (top down) Jeder Produktionsregel der Grammatik entspricht eine Funktion, die andere Funktionen aufruft. Terminale Symbole (0, 1, Namen der Inputs) werden von den Syntaxanalyse-Funktionen expr(), term() und prim() erkannt. Sobald beide Operanden eines (Unter-) Ausdrucks bekannt sind, wird dieser ausgewertet.
Der Parser verwendet eine Funktion get_token() für das Einlesen der Eingabe. Diese liest jeweils die nächste Basis-Einheit des Ausdruck ein und speichert diese in einer globalen Variablen. Vor jedem Aufruf einer Parser-Funktion wird das nächste Token von get_token ermittelt. Stößt get_token auf einen Namen, wird dieser mit der Funktion look() in dem Vektor der Inputs gesucht und der aktuelle Wert ermittelt.
Bei Aufruf des Parsers wird der Ausdruck um ein Return erweitert, welches zur Erkennung des Endes dient. Findet get_token() dieses Zeichen, wird der Auswertungsvorgang beendet und der Wahrheitswert des Ausdrucks zurückgeliefert. Tritt während des Auswertungsvorgangs ein Fehler auf, wird eine BadExpressionException geworfen, welche den Parser abrupt beendet.
Der Parser wird benötigt, um die logischen Ausdrücke der Übergangsbedingungen und Ausgabefunktionen (nur bei Mealy) auszuwerten.
Basis-Einheiten eines Ausdrucks sind die Operatoren UND (&), ODER (|) und NICHT (!), die Namen der Inputs als Eingangsvariablen und die Werte 0 und 1, sowie Klammern. Die Grammatik des Parsers lautet [St96]:
programm:
END
expression END
expression:
expression½ term
term
term:
term & primary
primary
primary:
number 0,1
name Inputs
(expression)
! primary
Die Syntaxanalyse geschieht im Stil des rekursiven Abstiegs (top down). Jeder Produktionsregel der Grammatik entspricht eine Funktion, die andere Funktionen aufruft. Terminale Symbole (0, 1, Namen der Inputs) werden von den Syntaxanalyse-Funktionen expr(), term() und prim() erkannt. Sobald beide Operanden eines (Unter-) Ausdrucks bekannt sind, wird dieser ausgewertet.
Der Parser verwendet eine Funktion get_token() für das Einlesen der Eingabe. Diese liest jeweils die nächste Basis-Einheit des Ausdruck ein und speichert diese in einer globalen Variablen. Vor jedem Aufruf einer Parser-Funktion wird das nächste Token von get_token() ermittelt. Stößt get_token() auf einen Namen, wird dieser mit der Funktion look() in dem Vektor der Inputs gesucht und der aktuelle Wert ermittelt.
Bei Aufruf des Parsers wird der Ausdruck um ein Return erweitert, welches zur Erkennung des Endes dient. Findet get_token() dieses Zeichen, wird der Auswertungsvorgang beendet und der Wahrheitswert des Ausdrucks zurückgeliefert. Tritt während des Auswertungsvorgangs ein Fehler auf, wird eine BadExpressionException geworfen, welche den Parser abrupt beendet.
Um entworfene Automaten weiterverarbeiten zu können, bietet JavaFSM die Möglichkeit, diese in die gängigen Formate VHDL und KISS zu konvertieren. Die Ausgabe des VHDL- / KISS-Codes erfolgt in ein Textfeld, von wo aus er mittels "Copy&Paste" lokal weiterverarbeitet werden kann.
VHDL ist eine inzwischen weltweit akzeptierte Hardware-Beschreibungssprache. Entwickelt wurde sie ursprünglich zur Dokumentation von Schaltkreisen: In Form von (lesbaren) Verhaltensbeschreibungen wird das nach außen sichtbare Verhalten definiert. Dabei kommen High-Level-Sprachkonstrukte wie IF-THEN-ELSE oder CASE zum Einsatz. Beim Schaltungsentwurf generieren sog. Synthese-Tools daraus fertige Schaltnetze bzw. -werke in Form von Gatternetzlisten. Diese können auf verschiedene Ziele (Zeit, Platz, ...) optimiert sein.
Da VHDL von einer Vielzahl von Tools unterstützt wird, dient es auch dem Datenaustausch. Front-End Tools generieren dabei auf Wunsch Compiler gerechten VHDL-Code, der von anderen Tools weiterverarbeitet werden kann .
Um mit JavaFSM erstellte endliche Automaten praktisch nutzen zu können, wird auch hier eine Export-Möglichkeit nach VHDL angeboten.
KISS kommt hauptsächlich in Verbindung mit programmierbarer Logik zum Einsatz. Es ist ein Technologie-unabhängiges Format, welches auf Wahrheitstabellen basiert. Neben diversen Features wie "don't cares", "subsets" etc. werden auch endliche Automaten unterstützt. Ein Design-File besteht aus einem Header mit Grundinformationen und einem Body mit den eigentlichen Logiktabellen. Die von JavaFSM verwendete Syntax ist in der folgenden Tabelle beschrieben:
| # | Kommentarzeile |
| .design name | Name des Designs |
| .inputnames name_1, [name_2 ...] | Hier werden alle Eingänge definiert (inkl. Clock- und Reset-Signal). In dieser Reihenfolge werden sie auch in der Wertetabelle aufgeführt. |
| .outputnames name_1, [name_2 ...] | Hier werden alle Ausgänge definiert. In dieser Reihenfolge werden sie auch in der Wertetabelle aufgeführt. |
| .clock signal sense | Einer der Eingänge wird hier als Clock-Signal
definiert
|
| async_reset signal sense state | Einer der Eingänge wird hier als Reset-Signal
definiert
|
| 010 z1 z2 01 | ein Zeile der Wertetabelle:
|
| 01- z1 z2 01 | Ein "-" in der Eingangsbelegung markiert ein "don't care". |
In JavaFSM wird von einer konkreten Zustandskodierung abstrahiert. Wird eine bestimmte Kodierung benötigt (z.B. als direkte Ausgabe), läßt sich diese in KISS wie folgt nachträglich definieren:
| .encoding | Zustandskodierung | ||||||
| state_name encoding |
|
![]()
![]()
![]()
![]()