
| |
 DescriptionThis applet demonstrates the finite state machine
often used for table-based branch-prediction
in modern microprocessors.
DescriptionThis applet demonstrates the finite state machine
often used for table-based branch-prediction
in modern microprocessors.
For background information about processor architecture in general, and dynamic branch prediction in particular, please check chapter 4 and section 4.5.2 ("branch prediction") from Andrew S.Tanenbaum, Structured Computer Organization (fifth edition, Pearson/Prentice Hall, 2005).
Most modern microprocessors are based on deep instruction pipelines (five to ten stages or even more) in order to achieve high clock rates. Unfortunately, the processor does not know in advance which code path to follow if a (conditional) branch instruction is encountered, and the target address of the branch needs to be calculated and might only become available after several clock cycles. This implies a heavy performance loss, as the pipeline has to be stalled until the branch condition has been evaluated and the branch target address is available.
The idea of branch prediction is to use extra logic to generate a fast (but possibly wrong) estimate for the branch condition and target address. The processor fetches and executes the predicted instructions at full speed, but needs to revert all intermediate results when the prediction turns out to having been wrong.
One popular and moderately efficent branch prediction scheme keeps a table of branch target addresses indexed by the address of the branch address. When encountering a branch instruction, the processor checks the table whether the branch is likely to be taken and for the probably branch target address (stored there during a previous execution of the same instruction). Later, after the branch instruction has been evaluated in full, the branch prediction table is updated. The problem with the scheme sketched above is a poor behevior for loops. After the first iteration of the loop, the branch target table will (usually correctly) predict the branch taken and point to the first instruction of the loop. Naturally, the last iteration of the loop will be mis-predicted, which results in the branch target table to be updated with 'branch-not-taken' data. As a result of this, the next time the loop is entered, the first iteration will be mis-predicted as well.
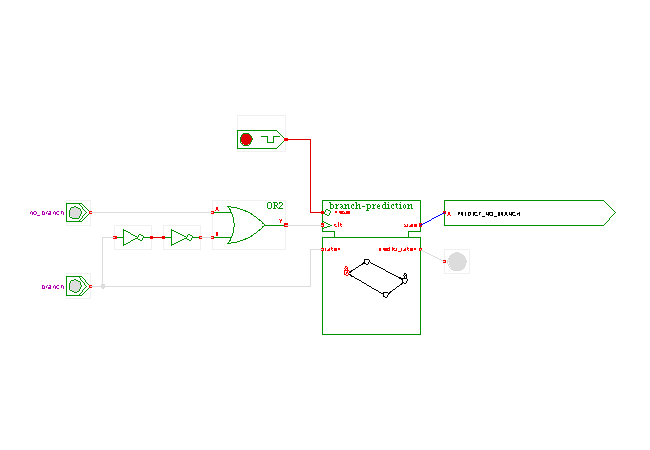
An improved strategy uses two status bits in the branch target table, based on the state machine shown in this applet. The basic idea is to give the prediction a 'second chance' and only change the prediction after it has failed two times in a row. This eliminates one mis-prediction for the loop situation explained above, and works as well for other frequent situations.
After a series of consecutive non-taken branches (for a given address), the FSM will be in the state PREDICT_NO_BRANCH and the output is a prediction of 'no branch'. If the prediction is wrong, it will move to the PREDICT_ONE_MORE_NO_BRANCH state and still predict 'non branch'. Only if the prediction turns out to be wrong again, it moves to the PREDICT_BRANCH state, otherwise it returns to PREDICT_NO_BRANCH.
To make playing with the state machine easier, pulse switches and a delay line are used to generate the clock pulse and the 'branch taken' input value for the state machine. Click the 'BRANCH' switch to simulate a taken branch instruction, and correspondingly for the 'NO BRANCH' switch. (When you click the 'BRANCH' switch, the delay line built from the inverters ensures that the pulse generated by the input switch arrives at the clock input a little later than at the 'taken' input, so that the setup and hold time conditions for the clock input are satisfied. Remember that delay-lines are not a recommended element for actual circuit designs and must be avoided for reliable circuits).
Run the applet | Run the editor (via Webstart)